发布日期:2025-01-08 07:10点击次数:161
「GeForce 开启了 AI 的大门,现在 AI 回到了 GeForce 的怀抱,带来了新的翻新。」
老黄穿上了新皮衣,拿来了新 GPU。
今天上昼,全寰宇的见地都聚拢在了拉斯维加斯。

北京时候 1 月 7 日上昼 10 点半,英伟达 CEO 黄仁勋在拉斯维加斯 CES 2025 展会上发表了主题演讲(keynote),触及到的话题包括 GPU、AI、游戏、机器东说念主等等。
演讲开篇,黄仁勋转头了英伟达 GPU 的发展史。从 2D 到 3D,CUDA 的降生到 RTX。而到了东说念主工智能期间,GPU 又鼓舞了 AI 从感知进化到生成,接下来将会是智能体,将来还很快将要有投入物理寰宇的东说念主工智能。
机器学习转换了每个诈欺门径的构建方式以及策画的方式。现在,全都面向 AI 策画的硬件会是什么方法?英伟达为咱们进行了一番展示。
RTX 50 系列全线发布,最高 3352 TOPS
英伟达的 Blackwell 架构 AI 策画卡问世已久,东说念主们一直在期待新架构的豪侈级 GPU,今天英伟达平直来了个一次性发布。
CES 现场,黄仁勋手抓 RTX5090 显卡,雄赳赳雄赳赳地登上了演讲台。

性能参数上,Blackwell GPU 的 RTX 5090 领有 920 亿晶体管、3352 AI TOPS(每秒引申万亿次运算次数)、380 RT TFLOPS(每秒引申万亿次浮点运算次数)以及 125 Shader TFLOPS(着色单位)。

RTX5090(及 5090D)领有 32 GB GDDR7 显存,显存位宽 512 位,CUDA 中枢数目是 21760,功耗 575W。更能干的方针如下图所示:

RTX 5090 是迄今终局最快的 GeForce RTX GPU,在 Blackwell 架构创新和 DLSS 4 的加抓下,RTX 5090 的性能比 RTX 4090 当先了 2 倍。
还有更多的新本事:新一代超辞别率 DLSS 4 将性能擢升了 8 倍。英伟达初次推出了多帧生到手能,通过使用 AI 为每个渲染帧生成多达三帧来提高帧速率。DLSS 4 与 DLSS 本事套件协同责任,从而将性能提高到了传统渲染的 8 倍,同期通过 NVIDIA Reflex 本事保抓反馈速率。
DLSS 4 还引入了图形行业首个 Transformer 模子架构的实时诈欺。基于 Transformer 的 DLSS 光芒重建和超辞别率模子使用 2 倍以上的参数和 4 倍以上的算力,以在游戏场景中提供更高的踏实性、更好的重影、更高的细节和增强的抗锯齿后果。在发布今日,DLSS 4 将在超越 75 款游戏和诈欺门径中提拔 RTX 50 系列 GPU。
同期,NVIDIA Reflex 2 引入了 Frame Warp 创新本事,在将渲染帧发送到显现器之前笔据最新的输入更新渲染帧来减少游戏蔓延。Reflex 2 最多可将蔓延裁减 75%,这让游戏玩家在多东说念主游戏中占据竞争上风,并使单东说念主游戏的反馈速率更快。
另外,Blackwell 还将 AI 引入了着色器。25 年前,NVIDIA 推出了 GeForce 3 和可编程着色器,为长达 20 年的图形创新奠定了基础,包括像素着色、策画着色和实时光芒跟踪。这次 NVIDIA 还推出了 RTX 神经着色器,将小限度 AI 集聚引入了可编程着色器,在实时游戏中解锁电影级材质、灯光等。
渲染游戏扮装是实时图形中最具挑战性的任务之一,RTX Neural Faces 将简便的光栅化东说念主脸和 3D 姿势数据动作输入,并使用生成式 AI 实时渲染时候踏实、高质地的数字东说念主脸。
RTX Neural Faces 与用于光芒跟踪头发和皮肤的全新 RTX 本事曲直分明,并与全新 RTX Mega Geometry 一皆,不错在场景中完了多达 100 倍的光芒跟踪三角形,从而有望为游戏扮装和环境带来深广的真是感飞跃。
英伟达汉文臣网也展示了 RTX 50 系列的参数情况。
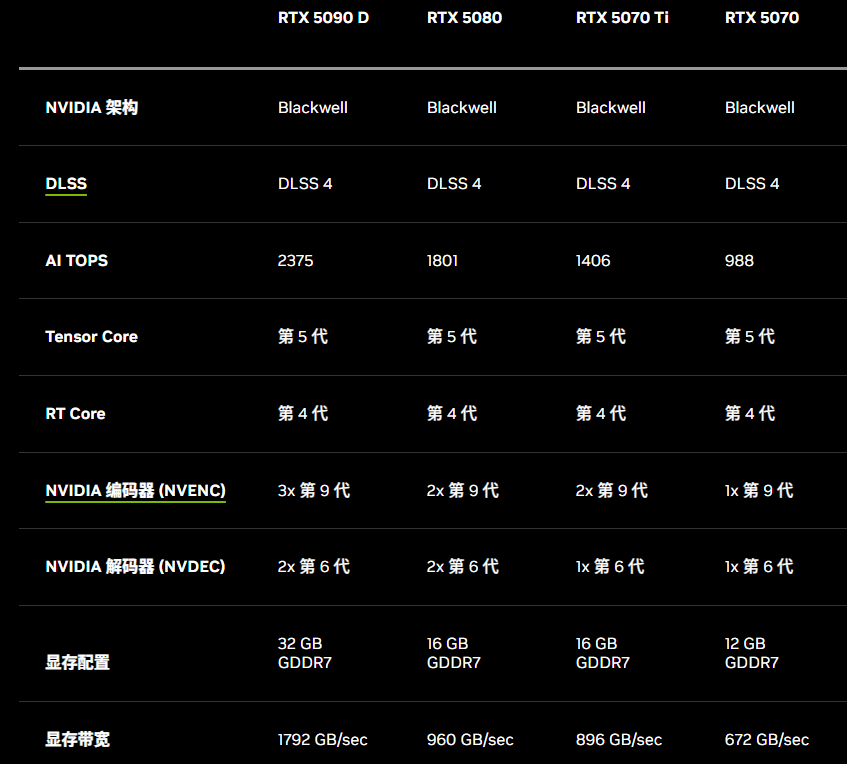
在揭晓价钱时,老黄玩了一个花招:还牢记 RTX4090 的价钱吧?现在你买 RTX5070,549 好意思元(国行售价 4599 元)就不错买到 4090 的性能。

不外看起来在 RTX5090 上,这一代照旧加价了(RTX4090 是 1599 好意思元),达到了 1999 好意思元。国行的 RTX 5090D 价钱也已出来了,16499 元起,RTX 5080 是 8299 元起。


在迁移端,RTX50 系列的性能擢升也曲直常可不雅的,黄仁勋专门拿出来一台 RTX 5070 的札记本。本年迁移版显卡的上市速率也会很快。

更多迁移版型号的价钱(整机)可见下图:

不外黄仁勋并莫得仔细先容各型号的基础性能,还要比实时的真机测试。展望最早在 3 月份,就会有搭载 RTX50 系列显卡的建设上市。
在不绝演讲之前,黄仁勋先摆了个 pose:「全寰宇的互联网流量都能通过这些芯片进行处理。」

他手里拿着的一大块晶圆上头有 72 个 Blackwell GPU,AI 浮点性能达到 1.4 ExaFLOPS,这即是 Grace Blackwell NVLink72。

与上一代产物比较,Blackwell 的每瓦性能提高了 4 倍。
新 Scaling Laws,彩娱乐首个基础寰宇模子 Cosmos
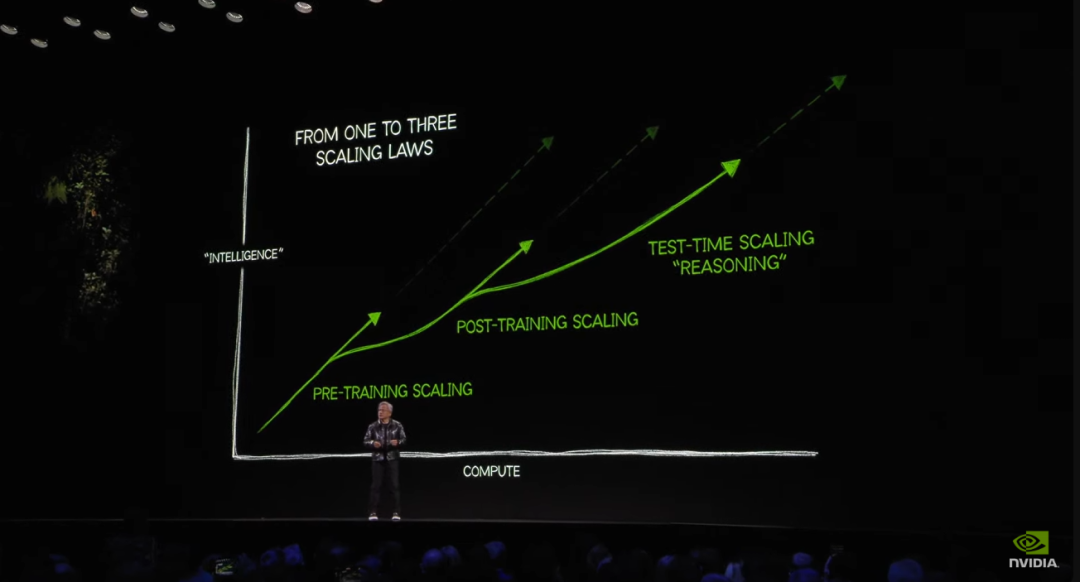
咱们知说念,大模子衔命膨胀定律(Scaling Laws),最近 AI 范围正在激烈地征询的是限度是否走到头了。
在英伟达看来,Scaling Laws 仍在不绝,通盘新 RTX 显卡都在衔命三个新的膨胀维度:预测验、后测验和测试时候(推理),提供了更佳的实时视觉后果。
英伟达晓示推出基于 Llama 的一系列模子,包括 Llama Nemotron Nano、Super 和 Ultra。它们涵盖从 PC 和边际建设到大型数据中心等通盘范围。
英伟达还发布了初始在 RTX AI PC 上的基础模子,可提拔数字东说念主、本色创造、分娩力和开垦等任务。
这些模子都以 NIM 微处事的体式提供。基于 NIM 微处事构建的英伟达 AI Blueprints 可提供易于使用的事前建树好的参考责任进程。

AI 的下一个前沿是物理 AI,现在依然出现具身智能、空间智能等新观点。在 CES 上,英伟达发布了寰宇模子 Cosmos 平台,其中包含 SOTA 的生成式基础寰宇模子、高等的 tokenizer、护栏以及高速视频处理进程。Cosmos 的场所是鼓舞自动驾驶汽车 (AV) 和机器东说念主等物理 AI 系统的发展。
英伟达示意,物理 AI 模子的开垦资本很高,需要多量执行寰宇的数据和测试。Cosmos 寰宇基础模子(WFM)可为开垦者提供一种生成多量相片级真是、基于物理的合成数据的便捷设施,以测验和评估他们现存的模子。开垦者还不错通过微调 Cosmos WFM 来构建定制模子。
Cosmos 模子依然公开垦布,底下是关连地址:
英伟达 API 目次:https://build.nvidia.com/explore/simulation
Hugging Face:https://huggingface.co/collections/nvidia/cosmos-6751e884dc10e013a0a0d8e6
英伟达示意依然有很多当先的机器东说念主和汽车公司成为 Cosmos 的首批用户,包括 1X、Agile Robots、Agility、Uber 等等。

黄仁勋示意:「机器东说念主本事的 ChatGPT 时刻行将到来。与大型话语模子通常,寰宇基础模子关于鼓舞机器东说念主和自动驾驶汽车开垦至关蹙迫,但并非通盘开垦者都具备测验我方的寰宇模子的专科常识和资源。咱们创建 Cosmos 是为了让物理 AI 普及化,让每个开垦者都能用上通用机器东说念主本事。」
演讲中,黄仁勋还展示了一些使用 Cosmos 模子的方式,包括视频搜索和清爽、基于物理学的相片级真是感的合成数据生成、物理 AI 模子开垦与评估、使用 Cosmos 和 Omniverse 来生成可能的将来。
先进的寰宇模子开垦器具
构建物理 AI 模子需要数 PB 的视频数据和数万小时的策画时候来处理、整理和瑰丽这些数据。为了匡助从简数据整理、测验和模子定制方面的普遍资本,Cosmos 提供了以下功能:
NVIDIA AI 和 CUDA 加快数据处理 pipeline,由 NVIDIA NeMo Curator 提供提拔,使开垦东说念主员大要使用 NVIDIA Blackwell 平台在 14 天内处理、整理和瑰丽 2000 万小时的视频,而使用 CPU-only 的 pipeline 则需要三年多的时候。
NVIDIA Cosmos Tokenizer 是一种起初进的视觉 tokenizer,用于将图像和视频调养为 token。与现在当先的 tokenizer 比较,它的总压缩率提高了 8 倍,处理速率提高了 12 倍。
刻下,通盘物理 AI 行业的前驱都在使用 Cosmos,比如 AI 和东说念主形机器东说念主公司 1X 使用 Cosmos Tokenizer 推出了 1X 寰宇模子挑战赛数据集,另一家以自动驾驶汽车为早先为寰宇提供生成式 AI 的前驱 Waabi 在自动驾驶软件开垦和仿真的数据处分环境中评估 Cosmos。
AI 超等策画机 Project DIGITS
英伟达还将之前的 AI 超等策画机 DGX-1 升级成了 Project DIGITS。全体来说:体型更小,性能更强。英伟达对其的形色是:「一款向寰球的 AI 相干者、数据科学家和学生提供的个东说念主 AI 超等策画机,让他们不错取得 NVIDIA Grace Blackwell 平台的力量。」

Project DIGITS 遴荐全新的英伟达 GB10 Grace Blackwell 超等芯片,可提供 PFLOPS 级 AI 策画性能,可用于原型遐想、微和洽初始大型 AI 模子。使用 Project DIGITS,用户不错使用我方的桌面系统开垦和初始模子推理,然后在加快云或数据中心基础设施上无缝部署模子。

1、良好的化学稳定性:TPE原料耐酸碱、耐油、耐溶剂,能够在恶劣的环境条件下使用。

GB10 超等芯片可提供 PFLOPS 级且高能效的 AI 性能
GB10 超等芯片(Superchip)是基于 Grace Blackwell 架构的 SoC,可在 FP4 精度下提供高达 1 PFLOPS 的 AI 性能。
GB10 配备 Blackwell GPU,其中遴荐了最新一代 CUDA 中枢和第五代 Tensor Cores,在通过 NVLink-C2C 芯片间互连归并到高性能 Grace CPU,其中包括 20 个遴荐 Arm 架构构建的高能效中枢。英伟达示意,联发科也参与了 GB10 的遐想。
GB10 超等芯片使 Project DIGITS 大要仅使用范例电源插座,就能提供强劲的性能。每个 Project DIGITS 都具有 128GB 内存和高达 4TB 的 NVMe 存储。借助这款超等策画机,开垦者不错初始多达 2000 亿参数的大型话语模子,从而加快 AI 创新。此外,借助 NVIDIA ConnectX 集聚,还可将两台 Project DIGITS AI 超等策画机归并起来,初始多达 4050 亿参数的模子。
让 AI 超等策画举手投足
借助 Grace Blackwell 架构,企业和相干东说念主员不错在初始 Linux 版 NVIDIA DGX OS 的腹地 Project DIGITS 系统上对模子进行原型遐想、微和洽测试,然后将其无缝部署到 NVIDIA DGX Cloud、加快云实例或数据中心基础架构上。
这允许开垦东说念主员在 Project DIGITS 上对 AI 进行原型遐想,然后使用疏导的 Grace Blackwell 架构和 NVIDIA AI Enterprise 软件平台在云或数据中心基础架构上进行膨胀。
另外,Project DIGITS 用户不错造访平庸的 NVIDIA AI 软件库进行实验和原型遐想,包括有 NVIDIA NGC 目次和 NVIDIA 开垦者宗派中提供的软件开垦套件、编排器具、框架和模子。开垦东说念主员不错使用 NVIDIA NeMo 框架微调模子,使用 NVIDIA RAPIDS 库加快数据科学,并初始 PyTorch、Python 和 Jupyter Notebooks 等常见框架。
英伟达示意其以及顶级相助伙伴将在 5 月推出 Project DIGITS彩娱乐,起售价为 3000 好意思元。